Database roles and access control


Database roles are used to manage database access permissions. A database role is an entity that contains information that define the following:
- Can you login?
- Can you create Database?
- Can you write to tables ?
Secondly, it defines what the client authentication system is
- Password
HOW TO CREATE A ROLE
Say, you're about to hire a bunch of data analyst in your company . You can create a role using :
CREATE ROLE data_analyst;
The information that defines what the current role can do is currently empty. However, you can create this alongside your role but not all. Let's say you're hiring an intern whose role ends at the end of the year. You can create a role in this manner:
CREATE ROLE intern WITH PASSWORD 'NewPassword' VALID TILL '2020-01-01';
Let's say you want to create an admin with the ability to create databases. You can create the role by:
CREATE ROLE admin CREATEBD;
If you would like to alter an already created role, you use the ALTER keyword
ALTER ROLE admin CREATEROLE;
The above alteration allows the admin to create roles too.
GRANT and REVOKE privileges from roles
You can grant and revoke privileges to roles using GRANT and REVOKE.
GRANT UPDATE ON ratings TO data_analyst;
The above command will grant data_analyst permission to update the ratings table. And you can REVOKE the privilege using;
REVOKE UPDATE ON ratings FROM data_analyst;
Here is a list of privileges for roles in SQL.

Please note that a role can be a user role or a group role. Think of the data_analyst role as a group role
CREATE ROLE data_analyst;
and inter as a user role
CREATE ROLE intern WITH PASSWORD 'NewPassword' VALID TILL '2020-01-01';
or
CREATE ROLE Alex WITH PASSWORD 'NewPassword' VALID TILL '2020-01-01';
Say you decide to add Alex to the data_analyst role, you can do that with:
GRANT data_analyst TO Alex;
With this , Alex can do data_analyst work now. If Alex does not need to do that work anymore, you can revoke that with;
REVOKE data_analyst FROM Alex;
POSTGRESQL has a set of default roles which provide to commonly needed privileges capabilities and information.

USE CASES
-- Create a data scientist role
CREATE ROLE data_scientist;
-- Create a role for Marta
CREATE ROLE marta WITH LOGIN
-- Create an admin role
CREATE ROLE admin WITH createdb CREATEROLE;
-- Grant data_scientist update and insert privileges
GRANT UPDATE, INSERT ON long_reviews TO data_scientist;
-- Give Marta's role a password
ALTER ROLE marta WITH PASSWORD 's3cur3p@ssw0rd';
-- Add Marta to the data scientist group
GRANT data_scientist TO Marta;
-- Celebrate! You hired data scientists.
-- Remove Marta from the data scientist group
REVOKE data_scientist FROM Marta ;
When tables grow, queries tend to be very slow even when we have set indexes correctly, these indexes can become larger that they don't fit into the memory. At a certain point, it can make sense to split tables into smaller parts. We call the process of doing this 'PARTITIONING'. The data we access is still the same but distributed over several physical entities. There are two kinds of partitioning, vertical and horizontal.
VERTICAL PARITIONING Vertical partition splits table vertically by using its columns which can be linked through shared key. This will improve query time for the tables.
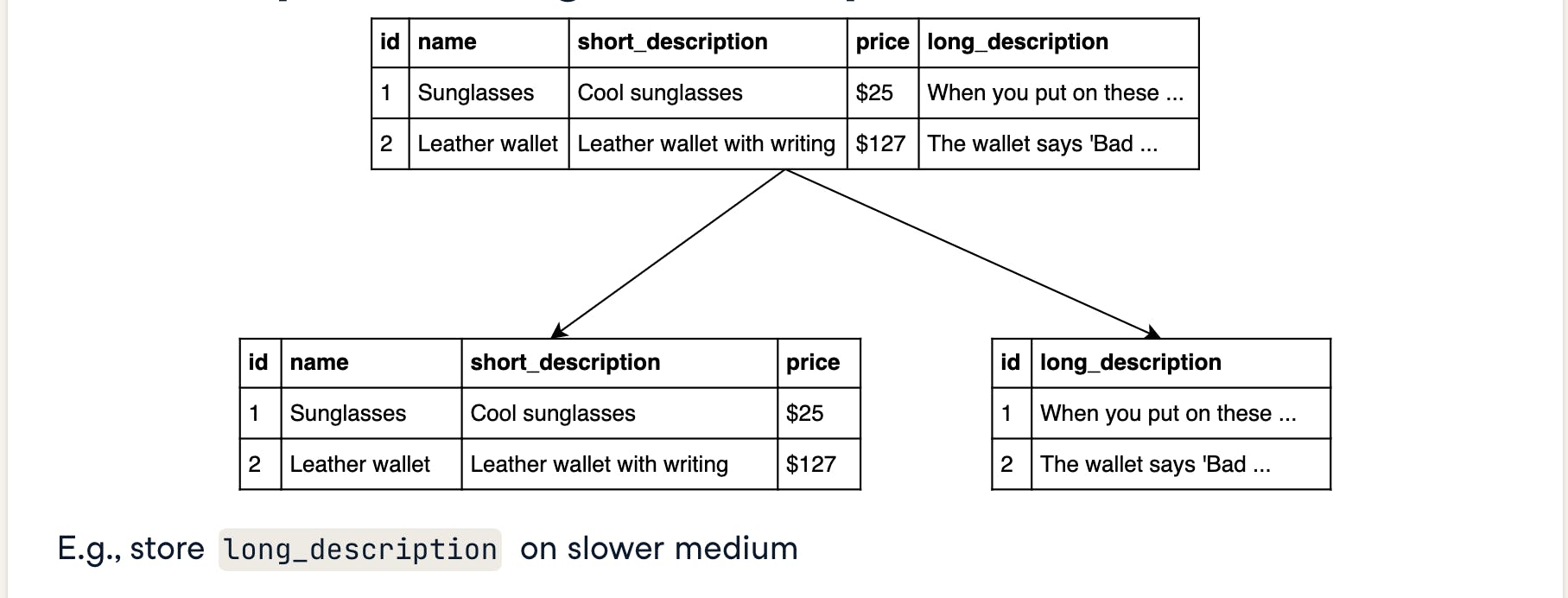
HORIZONTAL PARTITIONING In this partitioning, instead of splitting tables with columns, we split with rows.
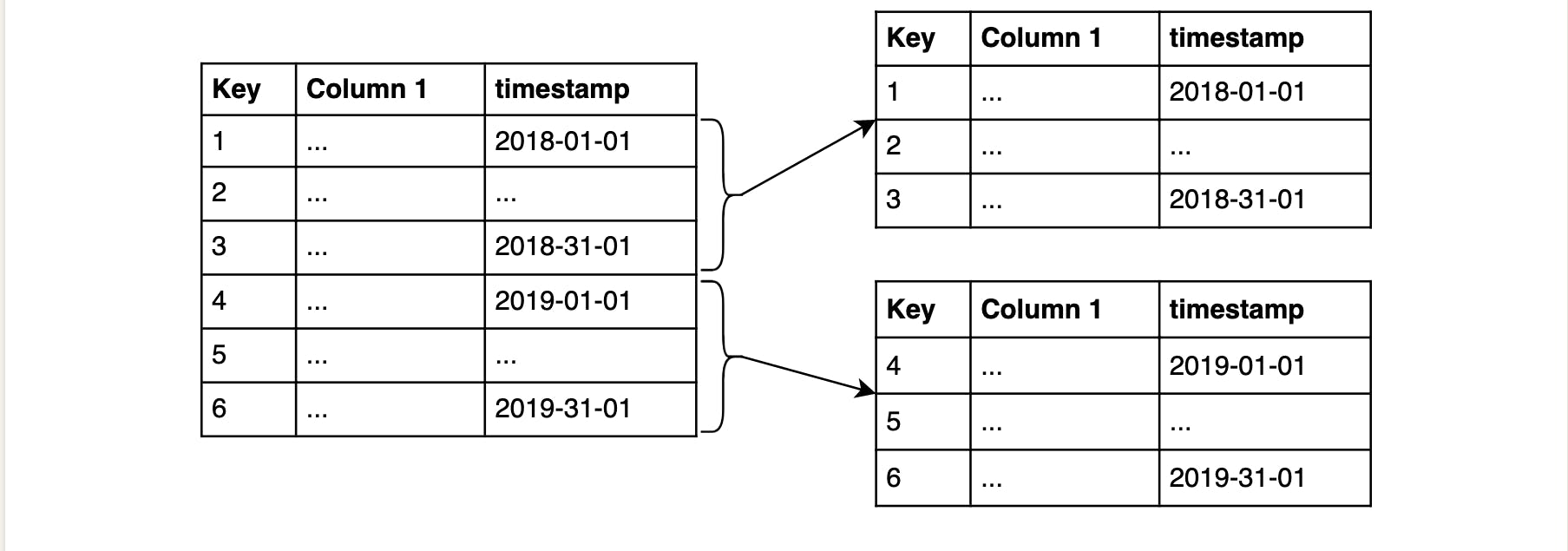
For example, you can split up tables with timestamp , so that all records relating to a particular year gets grouped together
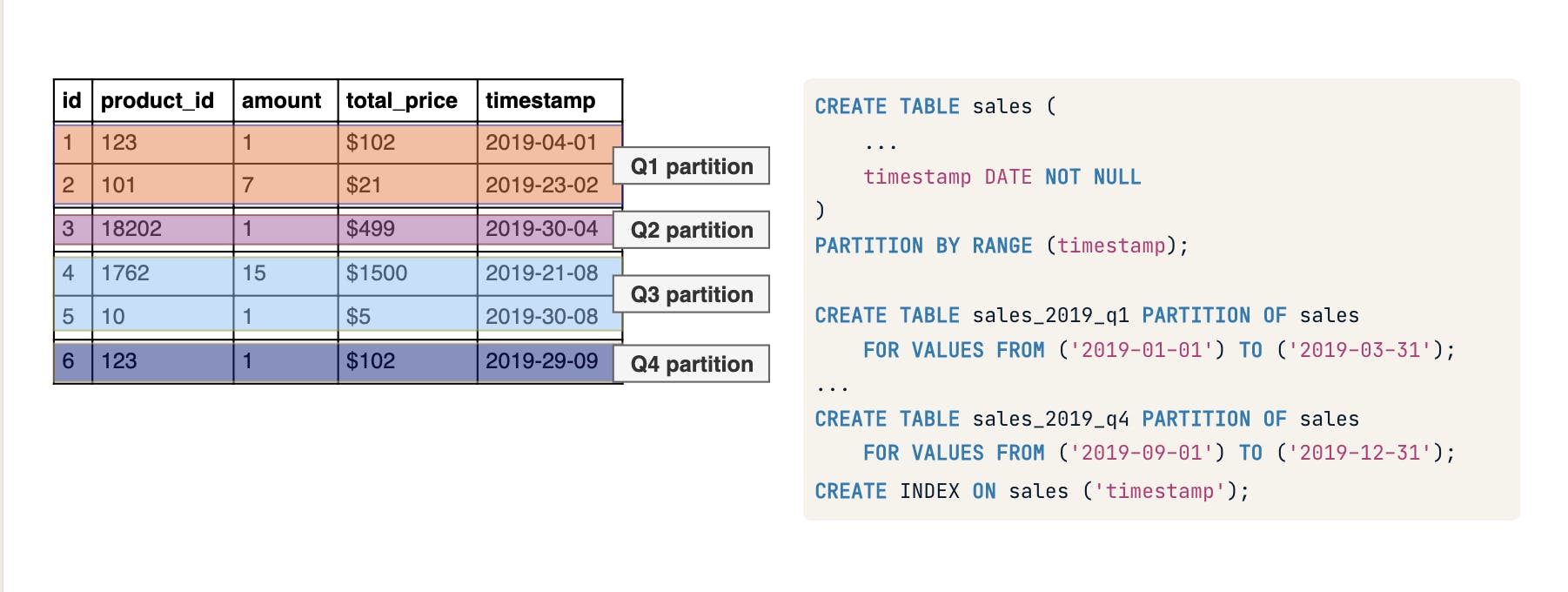
USE CASE
-- Create a new table called film_descriptions
CREATE TABLE film_descriptions (
film_id INT,
long_description TEXT
);
-- Copy the descriptions from the film table
INSERT INTO film_descriptions
SELECT film_id, long_description FROM film;
-- Drop the column in the original table
ALTER TABLE film DROP COLUMN long_description;
-- Join to create the original table
SELECT * FROM film
JOIN film_descriptions USING(film_id);
-- Create a new table called film_partitioned
CREATE TABLE film_partitioned (
film_id INT,
title TEXT NOT NULL,
release_year TEXT
)
PARTITION BY LIST (release_year);
-- Create the partitions for 2019, 2018, and 2017
CREATE TABLE film_2019
PARTITION OF film_partitioned FOR VALUES IN ('2019');
CREATE TABLE film_2018
PARTITION OF film_partitioned FOR VALUES IN ('2018');
CREATE TABLE film_2017
PARTITION OF film_partitioned FOR VALUES IN ('2017');
-- Insert the data into film_partitioned
INSERT INTO film_partitioned
SELECT film_id, title, release_year FROM film;
-- View film_partitioned
SELECT * FROM film_partitioned;
DATA INTEGRATION
Data integration combines data from different sources, formats , technologies to provide users with a translated and unified view of the data. There are few things to consider when integrating data:
- Your final goal
- The data source
- The data source format
- Which format should the unified data model take
- How often do you want to update the data?
After answering this questions, if your data source are different you want to transform the data so it fits into the unified data model. This can be hand-coded but you would have to make and maintain a transformation for each data source. Optionally, you can also use a data integration tool that provides the need ETL e.g APACHE AIRFLOW OR SCRIPTELLA. When choosing your tool, you must ensure that the it's flexible enough to connect to all data sources, reliable so that it can be maintained in a year and it should scale well , anticipating an increase in data volume and sources. You should have automated testing and proactive alerts so that if any data gets corrupted on its way to the data model, the system lets you know. Security is also a concern, if the data access was originally restricted it should restricted in the unified data model. For data governance purpose , you need to consider lineage : For effective auditing , you should know where all the data originated and where it is used at all times.